Este artículo es una reedición, con algunos extras nuevos, del que publiqué en la columna Informática recreativa en la ahora extinta web de Lola Cárdenas El rincón del programador. También fue publicada con mi permiso en programacion.com. Pido disculpas si algunos enlaces no funcionan. También pido disculpas por el uso repetido de la palabra decrementar a lo largo del texto, no reconocida en el DRAE.
Ser aficionado a la informática y no saber programar es algo que no casa bien. Un auténtico aficionado sabrá al menos hacer pinitos en algún lenguaje de programación, sea Java, Basic, Pascal, C o cualquier otro. Entre los lenguajes de programación también hay modas; un cierto lenguaje «se lleva» más que otros en ciertos momentos, lo cual es lógico habida cuenta de que la informática evoluciona y con ella las necesidades.
No muchos conocen, sin embargo, la inmensa variedad de lenguajes de programación que hay disponibles. Los nombres que ahora mismo me vienen a la cabeza sin consultar ninguna fuente de información son COBOL, ALGOL, APL, BASIC, RPG, Forth, Fortran, Lisp, PL/I, Logo, C, Pascal, Perl, Python, TCL, Ada, Java, ensamblador... y he omitido deliberadamente nombrar variantes como Visual Basic, RPG III, Scheme (un derivado de Lisp), C++ o Delphi (un Pascal ampliado).
Cuando llegamos al ensamblador, el tema de las variantes se convierte en locura. Cada modelo de microprocesador tiene su propio ensamblador, y existen miles y miles de modelos: Z80, PIC-16, 8051, 8086, 6809, 68000, 6502... A veces, como en el caso del 80x86 de Intel, hay varios, incluso multitud de dialectos: el dialecto oficial de Intel, el dialecto oficial del proyecto GNU (formato AT&T), el dialecto del ensamblador gratuito NASM...
Para liar aún más la madeja existen personas que inventan su propio lenguaje ensamblador, el de un procesador que no existe. El ejemplo más notable quizá sea el de Donald Ervin Knuth, matemático y escritor de una serie de tratados sobre computación famosos en todo el mundo. Existen simuladores de los dos lenguajes ensambladores que ha inventado, que corresponden a los procesadores imaginarios llamados MIX y MMIX.
Ahí no queda todo. Hay gente que no ve razón en que el lenguaje a inventar sea un lenguaje ensamblador; simplemente inventan un lenguaje nuevo. Las razones son muy variadas; está claro por ejemplo que Sun Microsystems tenía razones poderosas para inventar el Java. Pero no todo el mundo necesita razones poderosas; aquí vamos a tratar precisamente sobre los lenguajes de programación que han sido inventados por puro entretenimiento. ¿Hay gente capaz de eso? Sí, y no pocos. Incluso existen intérpretes de la mayoría de esos lenguajes, y en algunos casos hasta compiladores.
Uno de los primeros lenguajes esotéricos (al menos que yo tenga
referencia, pues fue creado en 1972), y quizá de los más extendidos,
es el INTERCAL.
Su diseño se fundamenta en la pretensión de crear un lenguaje
totalmente distinto a cualquier otro en todo, aunque sin olvidar
desde luego el sentido del humor. En él, tenemos que pedir por
favor la ejecución de ciertas sentencias; en lugar del conocido
«go to»
(ir a) para saltar a otra instrucción, tenemos que escribir
«come from» (venir desde) en el lugar de destino, aunque
esto es una extensión posterior a la primera especificación.
Podemos pedir que se abstenga de ejecutar ciertas sentencias,
por ejemplo:
PLEASE ABSTAIN FROM CALCULATING evita que se ejecute
la orden CALCULATE. Cuando
llegamos al capítulo sobre la precedencia de operadores se
nos explica que no la hay, porque precisamente el objetivo en el
diseño del lenguaje era que no hubiera ningún precedente.
Como resultado de esta regla, cuando necesitamos concatenar dos
operaciones juntas hay que agrupar los operandos por pares
mediante un equivalente a los paréntesis. El nombre completo del
lenguaje, según los autores, es
«Lenguaje Compilado Carente de Acrónimo Pronunciable», cuya
abreviatura es, «por razones obvias», INTERCAL. Podemos ver el
aspecto que tiene un programa escrito en INTERCAL en la
figura 1.
La función de este programa, extraído del manual de INTERCAL, es
leer dos enteros de 32 bits, tratándolos como enteros con signo
en formato de complemento a dos, y escribir su valor absoluto.
DO (5) NEXT
(5) DO FORGET #1
PLEASE WRITE IN :1
DO .1 <- 'V":1~'#32768$#0'"$#1'~#3
DO (1) NEXT
DO :1 <- "'V":1~'#65535$#0'"$#65535'
~'#0$#65535'"$"'V":1~'#0$#65535'"
$#65535'~'#0$#65535'"
DO :2 <- #1
PLEASE DO (4) NEXT
(4) DO FORGET #1
DO .1 <- "'V":1~'#65535$#0'"$":2~'#65535
$#0'"'~'#0$#65535'"$"'V":1~'#0
$#65535'"$":2~'#65535$#0'"'~'#0$#65535'"
DO (1) NEXT
DO :2 <- ":2~'#0$#65535'"
$"'":2~'#65535$#0'"$#0'~'#32767$#1'"
DO (4) NEXT
(2) DO RESUME .1
(1) PLEASE DO (2) NEXT
PLEASE FORGET #1
DO READ OUT :1
PLEASE DO .1 <- 'V"':1~:1'~#1"$#1'~#3
DO (3) NEXT
PLEASE DO (5) NEXT
(3) DO (2) NEXT
PLEASE GIVE UP
Los programas en INTERCAL, desde luego, no son fáciles de escribir. De todas formas no es el lenguaje esotérico en el que más cuesta escribir un programa. Por ejemplo, en lenguaje Piet es imposible escribir un programa: hay que dibujarlo. Vemos en la figura 2 un ejemplo de un programa en lenguaje Piet.
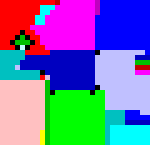
El programa de la figura 2 se limita a escribir la conocida frase «Hello, world!» («¡Hola, mundo!»). Hay que reconocer, sin embargo, que hemos hecho abuso del significado de la palabra escribir en este contexto. Diseñar el programa es algo que en Piet no es una tarea demasiado difícil.
Quien busque algo en lo que sea verdaderamente difícil programar,
puede intentar usar
Malbolge.
El nombre procede del Malebolge (el octavo círculo del
infierno de Dante), aunque seguramente el nombre fue recortado a causa de
una limitación del sistema operativo para el que fue originariamente
escrito (MS-DOS), que limita la longitud de los nombres a ocho caracteres.
Esta alusión al infierno puede dar una somera idea de la complicación del
lenguaje, aunque obtendremos una idea más aproximada conociendo la
dificultad que supuso para
Andrew Cooke
escribir un programa en Malbolge que simplemente escribiera
«Hello, world» (digamos que lo hizo por métodos de tipo
«ensayo y error», y ni siquiera consiguió uniformidad en las
mayúsculas y minúsculas ni signos de puntuación: el programa escribía
«HEllO WORld»). En la figura 3 vemos el programa que consiguió la hazaña.
(=<`$9]7<5YXz7wT.3,+O/o'K%$H"'~D|#z@b=`{^Lx8%$Xmrkpohm-kNi;g
sedcba`_^]\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543s+O<oLm
No hay que desesperarse por no entender nada. Esa es justo la intención que el inventor del lenguaje tenía. De hecho, el cripticismo buscado por el autor le resta cierto interés al lenguaje: está deliberadamente encriptado, razón por la cual Cooke propone un «Malbolge normalizado», que es lo que queda después de la fase de desencriptación. No hay que dejarse llevar por la idea, sin embargo, de que esto le reste dificultad al lenguaje. Se puede (si es que se puede) escribir un programa en Malbolge normalizado y después aplicar la fase final de encriptación para obtener un programa válido en Malbolge. La figura 4 muestra el aspecto del programa «Hello world» en Malbolge normalizado.
jpp<jp<pop<<jo*<popp<o*p<pp<pop<pop<jijoj/o<vvjpopoopo<ojo/o vooooooooooooooooooooooooooooooooooooooooooooooooooo*p<v*<*
Aunque resulta algo más legible que antes, sigue siendo complicado de descifrar sin una descripción de qué significa cada símbolo (y aun con ella). En el fichero de la distribución de Malbolge existe una descripción completa del lenguaje.
Pero de entre todos los lenguajes esotéricos hay uno que llama la atención por su exquisita simplicidad y potencia. Se llama Brainfuck, que en inglés suena tan mal como en español su traducción de Jodecerebros, con perdón. Debido a lo ofensivo del nombre, no es tan fácil buscar referencias en WWW usando buscadores ya que hay muchas variaciones del nombre para ocultar su carácter ofensivo: Brainf*ck, Brainf***, Brainfsck, BF... La intención de su creador, Urban Müller, era la de crear un lenguaje para el cual se pudiera escribir el compilador más corto del mundo.
A pesar del nombre, escribir un programa en Brainfuck no es tan difícil como cabe pensar. Está demostrado que es un lenguaje Turing-completo, lo que expresado de forma simple significa que se puede codificar cualquier algoritmo con él. Existen únicamente ocho instrucciones, cada una de las cuales está asociada a un símbolo. Hay un resumen en la tabla 1. Existe un puntero de programa, que representa la posición en la que se está ejecutando actualmente el código, como en cualquier otro lenguaje imperativo (con algunas salvedades), y un puntero de datos, que es una característica propia de Brainfuck y que sirve precisamente para manipular los datos. El puntero de datos apunta a la posición cero de una zona de memoria, inicialimente rellena de ceros. No se considera correcto un programa si intenta aplicar un decremento al puntero de datos cuando éste está en la posición cero. Usualmente se considera que el contenido de cada posición de memoria es un byte sin signo (un número de 0 a 255). Al incrementar uno de estos bytes cuando su valor era 255, generalmente pasa a valer 0. Al aplicarle un decremento cuando su valor era 0, generalmente pasa a valer 255. Decimos «generalmente» porque según la implementación puede haber versiones del lenguaje que adopten otros convenios.
| Instrucción | Descripción | Equivalente C |
|---|---|---|
- |
Restar 1 al contenido de la celda de memoria actualmente apuntada por el puntero de datos. | --*p; |
+ |
Sumar 1 al contenido de la celda de memoria actualmente apuntada por el puntero de datos. | ++*p; |
< |
Decrementar el puntero de datos en una unidad. Es un error ejecutar esta instrucción cuando el puntero de datos tiene el valor 0. | --p; |
> |
Incrementar el puntero de datos en una unidad. | ++p; |
[ |
Si el contenido de la celda de memoria a la que apunta el puntero
de datos es cero, buscar el correspondiente «]» y colocar
el puntero de instrucción inmediatamente después. Es posible
anidarlos. No se considera
un programa válido aquél en el que no hay un balance correcto entre
los «[» y los «]». |
while(*p){ |
] |
Colocar el puntero de programa en el «[» anterior
correspondiente. |
} |
, |
Introducir un carácter desde entrada estándar y colocarlo en la celda apuntada por el valor actual del puntero de datos. | *p=getchar(); |
. |
Escribir el carácter ASCII correspondiente al valor de la celda actual en la salida estándar. | putchar(*p); |
Aquellos que sepan C pueden valerse de las equivalencias aproximadas que se dan en la tabla para entender un poco mejor las acciones que cada instrucción realiza. Con tal sencillez estructural, mal puede sorprendernos la facilidad con la que se puede escribir un intérprete, y hasta un compilador de Brainfuck. Pero antes de entrar en detalles respecto al intérprete, analizaremos un poco el lenguaje y veremos algunas construcciones comunes.
Por ejemplo, la secuencia de instrucciones [-] se usa a
menudo en los programas Brainfuck, y sirve para poner a cero la celda de
memoria actual: equivale en C a la instrucción
«while(*p){--*p;}», es decir, mientras la celda
de memoria actual sea distinta de cero, decrementarla, lo cual obviamente
tiene como efecto ponerla a cero.
Si queremos mover el valor actual una posición a la derecha
(aquí entendemos que «izquierda» implica disminuir el
puntero de datos y «derecha» aumentarlo), utilizaremos el
siguiente programa: [>+<-]. Esto va incrementando el
byte de la derecha de la posición inicial y decrementando el actual,
hasta que éste es cero. Como resultado, al byte situado a la derecha de
la posición inicial se le suma lo que hubiera en dicha posición, que
acaba siendo cero. Suponiendo que a la derecha hubiera un cero, habremos
acabado moviendo el byte de esa posición un lugar a la derecha.
Copiar un valor es un problema más complicado; asumiendo que
las dos posiciones situadas a la derecha de la actual sean cero, se
procederá de la siguiente forma: primero, usaremos
[>+>+<<-], que tendrá el efecto de copiar el
valor en la posición actual a la posición de su derecha y a la siguiente
más a la derecha, y poner a cero la posición actual; después iremos dos
posiciones a la derecha usando >>, tras lo cual
usaremos una versión modificada del fragmento mover:
[<<+>>-], es decir, mover el byte de la
posición p (siendo p la posición del puntero de datos)
a la posición p-2. Al terminar, retrocederemos otra vez dos posiciones
usando <<, aunque dependiendo de la aplicación que
queramos darle este último paso puede ser innecesario.
Si no estamos seguros de si están a cero las dos posiciones de la
derecha de la actual, siempre podemos asegurarnos usando el siguiente
fragmento: >[-]>[-]<<. Normalmente,
sin embargo, no necesitaremos ejecutar este código, ya que estará
a cero al comenzar.
Juntando todo esto, nos damos cuenta de que si al empezar tenemos en la posición p el valor a, en la posición p+1 el valor 0 y en la posición p+2 el valor 0, tras ejecutar el siguiente fragmento de código acabaremos teniendo en p el valor a, en p+1 el valor a, y en p+2 el valor 0:
[>+>+<<-]>>[<<+>>-]<<
¿Confuso? Considerando cada parte por separado, se ve claramente que simplemente estamos construyendo fragmentos cada vez más grandes mediante los bloques básicos que anteriormente hemos considerado.
Multiplicar un byte por una constante es sencillo: basta con utilizar
el programa de mover, pero en lugar de incrementar una vez la variable de
la derecha, la incrementamos tantas veces como haga falta. Por ejemplo,
para multiplicar el byte actual por 7 podemos utilizar esto:
[>+++++++<-], que deja el resultado a la derecha del
byte actual, y éste a cero.
Multiplicar dos bytes entre sí requiere algo más de esfuerzo. La idea
es sumar el segundo sobre el byte a su derecha tantas veces como diga el
primero. Veamos cómo hacemos esto. Primero fijémonos en que la operación
de copiar puede ser usada también para sumar, puesto que si el valor en la
posición de la derecha de la actual no es cero, se le sumará el contenido
del byte actual. Así pues, si llamamos c a la operación
copiar, con este código resolveremos el problema: [>c<-],
es decir, ir a la derecha, sumar el byte que hay allí al siguiente, ir a la
izquierda, decrementar y continuar hasta que éste sea cero. Si se desea que
no se pierda el primer multiplicando, habrá que empezar copiándolo a un
lugar seguro.
El código completo queda así:
[> [>+>+<<-] >> [<<+>>-] << <-]
Veamos ahora un programa simple que imprime la
«respuesta a la Gran Pregunta de la Vida, el Universo y
Todo lo demás» (según Douglas Adams, escritor y humorista
británico fallecido hace pocos años). Dicha respuesta es 42. El
siguiente programa calcula el código ASCII del número 4 y lo
imprime, y a continuación calcula el código ASCII del número 2 y
lo imprime: +++++++[>+++++++<-]>+++.--.. El
código ASCII del dígito 4 es 52 = 7×7+3, por tanto primero
multiplicamos 7×7, y luego sumamos 3 al resultado y lo
imprimimos. Después restamos 2 a lo que quedaba, ya que el código
ASCII del dígito 2 es 50 = 52-2. Lo imprimimos, y ya lo tenemos.
Dejamos al cuidado del lector el resto del aprendizaje del
lenguaje Brainfuck, para centrarnos en una forma de elaborar un
intérprete de dicho lenguaje. Esta es una tarea realmente
sencilla, como veremos enseguida; la única parte que presenta
alguna complicación (poca, realmente) es llevar el balance de
qué «]» corresponde con un
«[» y viceversa. Precisamos de dos
memorias, compuestas por sendos arrays (o
arreglos, según algunos traductores): la de programa
y la de datos, llamadas respectivamente mp y
md. También necesitaremos dos variables:
p y d, que serán los punteros de
programa y datos, respectivamente.
He aquí un esquema del algoritmo principal del intérprete:
Leer el programa en la memoria de programa, mp,
guardando en la variable pfin la posición siguiente
a la última usada, que indicará fin de programa.
Poner a cero todos los elementos de la memoria de datos.
Hacer p = 0, d = 0.
Comienzo del bucle (1):
Si p = pfin, fin de programa: ir a la etiqueta (4).
Si la instrucción mp[p] es «-», hacer md[d] = md[d] - 1.
Si la instrucción mp[p] es «+», hacer md[d] = md[d] + 1.
Si la instrucción mp[p] es «<», hacer d = d - 1.
Si la instrucción mp[p] es «>», hacer d = d + 1.
Si la instrucción mp[p] es «,», leer un carácter y guardarlo en md[d].
Si la instrucción mp[p] es «.», escribir el carácter que hay en md[d].
Si la instrucción mp[p] es «[» y md[d] es cero, hacer lo siguiente:
Hacer nivel = 0.
Comienzo del bucle (2):
Si mp[p] es «[», hacer nivel = nivel + 1.
Si mp[p] es «]», hacer nivel = nivel - 1.
Hacer p = p + 1.
Si nivel = 0, ir al comienzo del bucle (1).
Ir al comienzo del bucle (2).
Si la instrucción mp[p] es «]», hacer lo siguiente:
Hacer nivel = 1.
Comienzo del bucle (3):
Hacer p = p - 1.
Si mp[p] es «]», hacer nivel = nivel + 1.
Si mp[p] es «[», hacer nivel = nivel - 1.
Si nivel = 0, ir al comienzo del bucle (1).
Ir al comienzo del bucle (3).
Hacer p = p + 1.
Ir al comienzo del bucle (1).
Etiqueta (4): fin de programa.
El intérprete recién descrito asume que los programas son
sintácticamente correctos, es decir, que tienen un balance
correcto de «[» y
«]» y que el programa nunca utiliza
la instrucción «<» cuando
d = 0, ni la instrucción
«>» cuando d está en
la última posición disponible de md. También
asume que el lenguaje efectúa correctamente el
«salto» de 255 a 0 al incrementar, y de 0 a 255
en los decrementos. Si esto no fuera así, habrá que poner
condiciones adicionales, convirtiéndose la operación de
incrementar en la siguiente:
Si md[d] = 255, hacer md[d] = 0; si no, hacer md[d] = md[d] + 1.
y la de decrementar, similarmente:
Si md[d] = 0, hacer md[d] = 255; si no, hacer md[d] = md[d] - 1.
Durante el desarrollo de un programa Brainfuck es fácil
equivocarse de forma que no cumpla los requisitos arriba
expuestos. Para evitar sorpresas es aconsejable incluir en el
intérprete comprobaciones en lugares estratégicos: comprobar
antes de decrementar d que éste no es cero, y
antes de incrementarlo que no está ya en el límite derecho; en
los bucles que buscan el «[» y
«]» correspondientes a su pareja, hay
que comprobar que no llegamos a p = 0 o a
p = pfin sin encontrar la pareja
correspondiente, o en caso contrario detener la ejecución. Con
esas precauciones el intérprete debería ser seguro frente a
cualquier programa Brainfuck por mal construido que esté.
Ya para terminar, una pregunta: ¿cuál es la longitud del programa Brainfuck más corto capaz de escribir una o minúscula (código ASCII 111) dejando el resto de la memoria de datos con ceros?
Intérprete en JavaScript
El siguiente intérprete puede servir para probar código en Brainfuck. Incluye entrada y salida, pero no ejecución paso a paso ni visualización de los datos (véase la sección de enlaces para un depurador de Brainfuck más completo en C).
Enlaces
Por ahora la mayoría de las páginas enlazadas desde aquí están en inglés, ya que el tema parece que todavía no es muy conocido en nuestro país. Esperemos que con el tiempo la situación cambie.
Sobre lenguajes esotéricos en general
El lugar por excelencia donde encontrar información y referencias
sobre lenguajes esotéricos es sin duda el Esoteric Languages
Wiki:
http://www.esolangs.org/wiki/
Hay un índice de páginas apuntadas a un webring sobre
lenguajes esotéricos, que también contiene multitud de referencias:
http://b.webring.com/hub?ring=esolang
Una excelente página dedicada a los lenguajes experimentales,
mantenida por Chris Pressey:
Cat's Eye, http://catseye.tc/
Es de destacar la sección dedicada a los lenguajes de programación
esotéricos:
http://catseye.tc/projects/eso.html
Eric S. Raymond es el autor de un compilador de INTERCAL, el C-INTERCAL.
Su página llamada The Retrocomputing Museum contiene una selección
de joyas del esoterismo en programación. Brainfuck tiene ocho
instrucciones, pero ¿cuál es el mínimo número de
instrucciones que debe tener un lenguaje para ser Turing-completo? ¡Una!
Hay en esta página dos ejemplos, que llevan el concepto del RISC un paso
más lejos: OISC (One Instruction Set Computing) y URISC (Ultimate RISC).
Otra de las joyas presentes en este museo es el kvikkalkul,
un lenguaje pretendidamente utilizado en los submarinos nucleares suecos
en la década de 1950, aunque más probablemente sea una broma. El lenguaje
sólo soporta números en coma flotante sin parte entera, es decir, menores
que 1.
También destacamos el MIXAL, que es el lenguaje ensamblador del
procesador MIX de Knuth, mencionado en el texto, y un lenguaje de
programación Klingon llamado var'aq. Hay muchas otras perlas que
invitamos a descubrir.
http://www.catb.org/esr/retro/
La Enciclopedia de Lenguajes Estúpidos contiene una lista bastante
exhaustiva de lenguajes esotéricos, sus características, el nombre de su
creador, el año de creación y la página principal. Varios de los enlaces
disponibles aquí han sido obtenidos gracias a esa página.
http://www.kraml.at/stupid/
Listas de correo relacionados con lenguajes
esotéricos:
Archivo de la lista de correo de Cat's Eye
Selección de lenguajes esotéricos concretos
El lenguaje Whenever, cuyas instrucciones no
se ejecutan en un orden preestablecido sino aleatorio:
http://www.dangermouse.net/esoteric/whenever.html
Las instrucciones del lenguaje Wierd son cambios
de dirección en cadenas de símbolos. Esta es la especificación
del lenguaje:
http://catseye.tc/projects/wierd/doc/wierdspec.txt
El lenguaje Piet mencionado en el texto, cuyas
instrucciones son colores:
http://www.dangermouse.net/esoteric/piet.html
Descripción del lenguaje nihilista Sartre, creado por J. Colagioia,
otro lenguaje pensado con buen humor. Es bastante llamativa
la definición de la instrucción condicional IF.
http://catseye.tc/projects/sartre/doc/sartre.html
Sobre Brainfuck
He aquí un intérprete y depurador de Brainfuck escrito por el
autor de este artículo (en inglés), suministrado en forma de código
fuente en C. El código debería ser sumamente portable; compila
perfectamente con gcc tanto en Windows como en Linux. El
intérprete, además, realiza primero una pasada de optimización
del código para que se ejecute más rápido. El depurador contiene
funciones avanzadas que hasta ahora no he encontrado en ningún
programa similar.
brfd101.zip (11.077 bytes)
Una completa guía acerca de los bloques con los que construir
programas en Brainfuck:
http://home.planet.nl/~faase009/Ha_bf_intro.html
La demostración formal de que Brainfuck es Turing-completo:
http://home.planet.nl/~faase009/Ha_bf_Turing.html
Un intérprete de Brainfuck disponible en línea, escrito en JavaScript:
http://home.planet.nl/~faase009/Ha_bf_online.html
Propuestas de normalización del Brainfuck:
http://www.muppetlabs.com/~breadbox/bf/standards.html
y otra con cierto sentido del humor:
http://esoteric.sange.fi/ENSI/brainfuck-1.0.txt
Existen numerosos programas escritos en lenguaje Brainfuck; entre ellos destacamos un programa para averiguar si un número es primo, varios intérpretes y compiladores de Brainfuck escritos precisamente en Brainfuck, y un programa para calcular PI, aunque éste último requiere una extensión del lenguaje que permita que cada celda pueda almacenar números de 16 bits en vez de 8.
He aquí una biblioteca de programas escritos en Brainfuck. Destacamos
el programa SORT.BF, que lee una entrada, la ordena mediante el método de
la burbuja e imprime el resultado.
http://esoteric.sange.fi/brainfuck/bf-source/prog/
Otros enlaces indirectamente relacionados con lenguajes esotéricos
Una colección del programa Hello, World escrito en
gran variedad de lenguajes, incluyendo muchos esotéricos, entre
ellos BrainFuck e INTERCAL:
http://www.latech.edu/~acm/HelloWorld.shtml
99 Bottles of Beer es una canción popular inglesa y
estadounidense, al estilo de la canción popular española cuya letra
empieza así: Un elefante se balanceaba sobre la tela de
una araña... La versión en inglés requiere contar del 99 al
cero durante la canción. Escribir su letra es un ejercicio de
programación indudablemente más complicado que el de Hello,
World, ya que requiere un bucle finito, una cuenta atrás e
imprimir números, y por ello los programas tienden a ser más
largos pero a la vez más interesantes. He aquí una página dedicada
a los programas que imprimen la letra completa de la canción
99 Bottles of Beer
en diferentes lenguajes de programación; destacamos el escrito en
A+ ya que es capaz de imprimir las versiones europea y
americana. Por supuesto no faltan versiones Brainfuck ni INTERCAL del
programa, e incluso una en Malbolge.
http://www.99-bottles-of-beer.net/
Los quines son programas capaces de reproducirse a sí
mismos. No tienen, sin embargo, nada que ver con los virus: a
diferencia de éstos, el requisito que han de cumplir los quines
es que la salida del programa sea su propio código fuente, sin
utilizar ningún fichero externo. Pensando un poco sobre el tema
vemos enseguida que la tarea no es trivial, y que se parece al
problema del huevo o la gallina. Hay ejemplos en muchos
lenguajes, entre ellos INTERCAL y Brainfuck.
http://www.nyx.net/~gthompso/quine.htm
Lista exhaustiva de lenguajes de programación, antiguos y modernos:
http://ftp.wustl.edu/doc/misc/lang-list.txt
La Galería de los Descifradores CSS es una página creada para
defender que un programa de ordenador puede ser acogido dentro de
la ley de libertad de expresión, ya que al parecer un juez
estadounidense declaró ilegal un programa escrito en lenguaje C
que descifraba los sectores encriptados de los discos DVD, que
utilizan un sistema criptográfico denominado CSS. Hay ejemplos
en muchos otros lenguajes (entre ellos, cómo no, Brainfuck), y
otras muchas formas de expresar el programa original: versiones
recitadas del programa en formato MP3, descripciones detalladas
del algoritmo paso a paso que pueden ser utilizadas para
rehacerlo, y muchas otras divertidas maneras de convertir el
algoritmo a formas que sí están claramente protegidas por la
libertad de expresión. Dando vueltas a la tuerca, lleva el tema
a extremos que rayan el ridículo, como la existencia de números
primos ilegales.
http://www.cs.cmu.edu/~dst/DeCSS/Gallery/

No comments:
Post a Comment