Hay un filtro para GIMP que puede dar buen resultado aplicado a logos u otros propósitos espectaculares, pero cuya utilidad se ve limitada por la forma en que es aplicado. Estoy hablando de Viento.
El filtro Viento sólo se puede aplicar horizontalmente, hacia la izquierda o hacia la derecha. Esto limita mucho su campo de aplicación, pese a que si pudiera aplicarse de forma radial desde un punto de la imagen hacia los bordes, se podrían conseguir efectos interesantes.
Aquí vamos a ver cómo esquivar esa limitación y aplicar el filtro radialmente. Para ello nos ayudaremos de otro filtro presente en ese mismo menú: Coord. polares.
Hace nada compilé un paquete de Gimp 2.6.8 para Debian Lenny, así que es la versión que vamos a usar en este tutorial. En este caso apenas hay diferencias respecto a la 2.4, pero trataré de explicar las que recuerde.
Primero, dejemos claro el objetivo que perseguimos mediante un par de ejemplos:
Logotipo creado con Archivo > Crear > Logotipos > Calor resplandeciente... (en Gimp 2.4 los logotipos están en el menú Xtns de la ventana de herramientas).
Resultado de aplicar el efecto Viento de forma radial
Peluso
Peluso con efecto viento radial
En el caso del logotipo, para que aparezca el texto bien perfilado he aplicado el efecto solamente a la capa central, ya que la superpuesta ayuda a perfilar; he hecho la prueba de aplanar primero la imagen para aplicar el efecto a todo, pero se emborronaba mucho.
Para ver si el efecto queda aceptable o no, a modo de quickie, bastará con aplicar los pasos cuarto, quinto, sexto, séptimo y noveno (transformación, giro, aplicar efecto, deshacer giro, deshacer transformación), que son los que comprenden la esencia del método. Nos quedará un círculo en pequeño en el centro, pero con suerte bastará para que podamos decidir si vale la pena intentar el método completo o no.
Paso cero: ¿Tiene nuestra capa canal alfa? ¿Lo necesita? ¿Hay que ajustar el color de fondo? ¿Hay que duplicar la capa?
Este tutorial puede aplicarse tanto a capas con canal alfa, como a capas sin él. Al final del proceso, se nos puede haber contaminado la imagen con píxels que no pertenecen a ella, que serán transparentes si hay canal alfa, o del color del fondo si no lo hay. Si tiene alfa, después se puede colocar la imagen original debajo para disimular, pero si se trata de un color plano, basta con asignárselo al color de fondo y nos ahorraremos algún paso. Así que, si no tiene canal alfa, decidamos primero si lo añadimos o no y, en caso de que no, ajustemos el color de fondo. Por ejemplo, si es una capa que contiene un logo en blanco sobre fondo verde homogéneo, se puede ajustar el color de fondo a ese verde y trabajar sin canal alfa. Si lo vamos a hacer con una fotografía, como la de Peluso, lo que mejor resultado proporcione será probablemente duplicar la capa y añadir alfa si no tiene, de manera que la imagen original quede debajo, para que así las partes contaminadas por transparencia dejen a la vista dicha imagen. En cualquier caso, es una buena idea tener una copia de la capa original como referencia, para facilitar el último paso de recorte.
Primer paso: Recentrar
Nuestro primer paso será escoger cuál va a ser el punto central del que van a salir todos los «rayos». En el caso de Peluso, he escogido el punto (284, 276). El filtro Coord. polares toma como centro el de la capa con la que trabaja, así que vamos a ampliar el tamaño de manera que dichos puntos queden en el centro. Si queremos que el centro coincida con el de la imagen, este paso no será necesario. En el caso del logo, he optado por ello y me lo he saltado.
La forma de conseguir el nuevo centro es: averiguar las distancias desde el centro escogido (en coordenadas relativas a la capa) hasta ambos lados de la capa, averiguar la mayor de las dos, y agrandar la capa al doble de dicha distancia, recolocándola de forma que nuestro centro elegido caiga en el centro de la versión agrandada. Esto se hace tanto para la coordenada horizontal como para la vertical. Aquí, «agrandar» no se refiere a escalar, sino a cambiar el tamaño extendiendo el borde. Es la operación que en el Gimp se llama «Tamaño del borde de capa...».
La imagen de Peluso tiene 640×480 píxels. La distancia del centro elegido al borde izquierdo es 284; al borde derecho, es 640-284=356. Por tanto, tenemos que expandir la capa por su lado izquierdo dejando una imagen de 356·2=712 píxels de ancho. Repetimos lo mismo con las coordenadas verticales: la distancia al borde superior es 276 y al borde inferior es 480-276=204 píxels, por lo tanto está más cerca del inferior, luego habrá que expandirlo por debajo hasta que la imagen llegue a 276·2=552 píxels de alto. Es decir, tras redimensionar la capa, ésta ha de quedar pegada a la esquina superior derecha. Así que vamos a Capa > Tamaño del borde de capa, quitamos la cadenita que liga el tamaño vertical y el horizontal e introducimos en Anchura, 712, y en Altura, 552 (píxels, claro). En Desplazamiento, como queremos llevarla a la esquina superior derecha, subimos X al máximo, que es 72, e Y la dejamos a 0. Pulsamos Redimensionar. Ahora el centro de la capa ya es el que queremos.
Segundo paso: Agrandar
Dada la manera en que vamos a usar el filtro Coord. polares, vamos a tropezar con el problema de que la imagen final va a ser más pequeña que la inicial. Concretamente, con forma de un círculo cuyo diámetro es la menor de las dimensiones de la capa. Para compensar este efecto, hemos de agrandarla de antemano de forma que la parte original quede inscrita dentro de dicho círculo.
Resultado de aplicar el filtro Coord. polares y su inverso. Arriba, sin agrandar la capa primero; abajo, agrandándola. Obsérvese que en la de abajo la imagen original queda completa.
Este tamaño extra se aplica incluso si ya la hemos agrandado en el primer paso, y después de hacerlo; así el botón Centrar hará lo que esperamos.
Para saber el radio del círculo dentro del cual estará nuestra capa inscrita, hemos de echar mano del teorema de Pitágoras. Primero, hay que hallar el centro; esto lo hacemos dividiendo los tamaños horizontal y vertical por 2. Con la imagen de Peluso, el horizontal es 356 y el vertical, 276. El punto más alejado de dicho centro es la esquina (todas ellas), así que hay que calcular la distancia a la misma. Aplicamos Pitágoras: (356²+276²)½ ~= 450,45. Al final del proceso, debido a errores de precisión acumulados se colarán unos pocos píxels indeseados; para compensarlo, añadimos un 1% (el error máximo que he observado no llega a 0,4% pero más vale estar seguros, ya que va a ser una diferencia pequeña). Redondeamos por lo alto para estar más seguros aún. Buscaremos, pues, un círculo de 455 píxels de radio, o sea, 455·2=910 píxels de diámetro, así que agrandamos la capa para que sea un cuadrado capaz de circunscribir dicho círculo, es decir, le damos un tamaño de 910×910. Para ello, vamos de nuevo a Capa > Tamaño del borde de capa, quitamos la cadenita, introducimos Anchura = 910, Altura = 910 y pulsamos el botón Centrar para que nos centre el contenido actual. Si hemos escogido un centro distinto, podemos ver el resultado un poco descentrado al pulsar el botón; eso es normal y no debe preocuparnos, pero nuestro centro sí debe estar en el centro del cuadrado resultante; si no es así, quizá hemos colocado la capa en el cuadrante incorrecto en el paso anterior y hay que volver atrás. Si todo ha ido bien, pulsamos Redimensionar.
Para el logo, de 526×238, los valores son (263²+119²)½ ~= 288,67, que multiplicado por 2,02 (el doble más el 1%) y redondeado al alza nos da que la capa debe ser de 584×584.
Tercer paso: Extender los bordes
La capa del logo con la que vamos a trabajar no llega hasta los bordes, así que si se contamina un borde con transparencia a causa de los errores de precisión, no pasa nada; en ese caso podemos pasar al paso siguiente. El caso de Peluso es distinto, porque la fotografía sí que llega hasta los bordes. Si no nos preocupa que se haga un poco transparente en los bordes, podemos saltar este paso. Si estamos aplicando el truco descrito en el Paso Cero, dejando una copia de la imagen en la capa inferior, no lo necesitaremos. Si el borde queda mal incluso al usar esa estratagema, podemos probar con el truco aquí descrito.
La intención es extender cada borde a su correspondiente espacio vacío. No conozco ninguna forma que no sea tediosa. La idea es seleccionar la fila de píxels superior (una selección de Ancho×1), copiarla y pegarla en el espacio vacío superior, escalándola sólo verticalmente y moviéndola para cubrir la totalidad del mismo. Para ver lo que hacemos, es preferible haber hecho primero Imagen > Ajustar lienzo a las capas. Cuando hayamos terminado, hacemos lo mismo con la fila de píxels inferior. Después, con la fila de píxels izquierda (una selección de 1×Alto) y por último, con la derecha. Al hacer la izquierda y la derecha, cogeremos también lo que ya hemos extendido al hacer la parte de arriba y la de abajo.
Por ejemplo, así queda Peluso tras este paso:
Peluso con los bordes extendidos de la forma recién descrita.
Cuarto paso: Polares a Cartesianas(*)
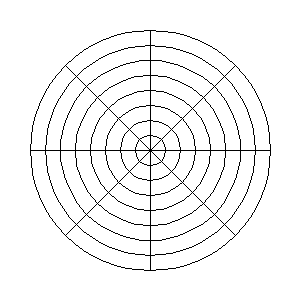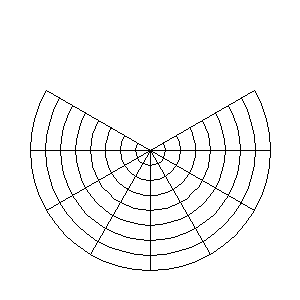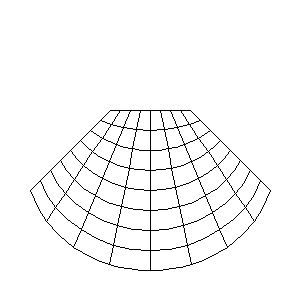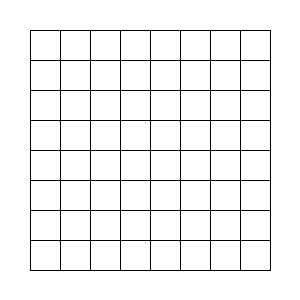
Vamos al meollo del asunto. Abrimos el filtro Coord. polares y desmarcamos la casilla «A polares», dejando todo lo demás por defecto (profundidad circular 100%, ángulo de desfase 0, no mapear al revés, sí mapear desde arriba). Obtenemos una versión deformada de la imagen de partida. La transformación interpreta la imagen original como si estuviera en coordenadas polares y representa en el eje X, el ángulo, y en el Y, el radio relativo a la menor de las dos dimensiones de la imagen(*). Es decir, todos los efectos que apliquemos verticalmente se harán sobre el radio. Mmmm, eso se parece a lo que queremos.
Actualización 2-2-2010. Esta animación muestra qué transformación realiza el filtro Coord. Polares al aplicarlo a una imagen habiendo marcado las casillas «Mapear al revés» y «Mapear desde arriba» y con la casilla «A polares» desactivada.
Quinto paso: Rotación de 90° a la izquierda
Pero el efecto Viento no opera en dirección vertical, sino únicamente horizontal, así que antes de aplicarlo, primero rotamos la imagen 90° hacia la izquierda con Capa > Transformar > Rotar 90° en sentido antihorario.
Sexto paso: Aplicar el efecto
Ahora es cuando aplicamos el filtro Viento. Hemos de jugar con los ajustes hasta que consigamos lo que buscamos. En el caso de Peluso, he usado Borde Trasero, Umbral 12 y Fuerza 30, dejando Estilo y Dirección intactos. Con el logo, he usado Borde Delantero, Umbral 10 y Fuerza 100.
Séptimo paso: Rotación de 90° a la derecha
Para poder devolver la imagen a su estado inicial con el efecto aplicado, tenemos que deshacer las transformaciones que hemos acumulado. Primero, la giramos a la derecha 90° con Capa > Transformar > Rotar 90° en sentido horario.
Octavo paso: Ampliar (Antialias primera parte)
El filtro Viento produce unas líneas muy finas, de un píxel de ancho, lo cual causa problemas de aliasing al convertir la imagen de nuevo a polares(*), que sería el paso siguiente si no fuera por ese problema. Según la imagen, podemos tener suerte o no, y no he encontrado otra forma de averiguarlo que el ensayo y error. Con Peluso no lo he necesitado; con el logo, sí.
Para conseguir un antialiasing que palie esa pega, el truco que empleamos es ampliar la imagen en este momento, de tal forma que las líneas que se convertirán de cartesianas a polares(*) sean más gruesas, para que después, al reducir con Sinc una vez convertido, sea la propia interpolación la que consiga el antialias. Así que, si hemos tenido en un intento anterior problemas de aliasing, ahora es el momento de ampliar la capa usando Capa > Escalar capa. Recomiendo un valor que no sea un múltiplo exacto como 200%, porque lo he probado y ha sido un fracaso; en cambio, usando un 121% de ampliación he tenido éxito.
Aquí se ve la diferencia sin antialias y con él:
Comparación entre no usar antialias y usarlo
Noveno paso: Cartesianas a Polares(*)
Abrimos de nuevo Coord. polares y marcamos la casilla «A polares» sin tocar nada más. En la previsualización, veremos ya un anticipo del resultado final. Aceptamos.
Actualización 2-2-2010. Esta animación muestra qué transformación realiza el filtro Coord. Polares al aplicarlo a una imagen habiendo marcado las casillas «Mapear al revés» y «Mapear desde arriba» y con la casilla «A polares» activada.
Décimo paso: Reducción (Antialias segunda parte)
Ahora hay que deshacer la ampliación realizada en el octavo paso, si la hemos hecho. Para ello, podemos usar como tamaño destino el tamaño de la imagen en píxels obtenido en el segundo paso (910×910 para Peluso).
Undécimo y último paso: Recortar
Ya solo falta recortar la capa. Esto puede ser complicado si no tenemos una capa de referencia con el tamaño y la posición originales. Si contamos con ella, podemos seleccionarla, usar Capa > Transparencia > Alfa a selección, y luego elegir la capa procesada y usar Capa > Recortar a la selección. Esta última opción no recuerdo que estuviera en Gimp 2.4, así que a quien lo tenga puede que le toque hacer el recorte artesanalmente.
(*): Yo diría que la caja de selección «A polares» está al revés: que cuando está desmarcada es cuando convierte a coordenadas polares y viceversa, representando en un eje el ángulo y en el otro el radio. Por tanto, la primera transformación sería de cartesianas a polares y la transformación inversa convertiría de polares a cartesianas, y no al revés como indica la casilla. Agradecería opiniones al respecto.
Variaciones
El efecto Viento no es el único que se beneficia de esta técnica, así que hay otras opciones para los pasos quinto a séptimo. Otro efecto que no se puede aplicar radialmente es Desplazamiento, aunque en este caso tiene la opción de aplicarlo tanto horizontal como verticalmente, por lo cual si queremos probarlo podemos omitir el paso de la rotación de 90°. No he encontrado aún una utilidad al resultado. Otro posible uso es el Desenfoque gaussiano, ajustando el radio X a cero. Más efectos curiosos: Pixelizar, Mosaico de cristal, Ondular, Borrar las otras filas... Lo que se le ocurra a cada uno.
Nota final
Después de escribir este tutorial, me he dado cuenta de que alguien ya había escrito uno similar: http://www.gimpusers.com/tutorials/rays-of-light-behind-text.html. Sin embargo, he preferido publicarlo porque proporciona valor añadido al explicar cómo recentrar y cómo ampliar la capa en caso de que no sea un logo sino otro tipo de imagen, y explica un método de antialiasing más sofisticado que el que sugiere el autor de ese otro tutorial. El hecho de que ambos tutoriales consten de once pasos es mera coincidencia.